

A staggering 93% of businesses that suffer a data disaster with no disaster backup plan are out of business within a year. But with ReBid, this burden is not yours to shoulder. We plan to protect your marketing data with a strong infrastructure. This 2-part series tells you all about our approach to high availability and disaster recovery planning.
Our application stack is hosted on the AWS Cloud. We use AWS as it is simple to use, flexible, cost effective, reliable, and scalable, with highly available performance and stability. It is the largest cloud player, with a larger community support and user base. AWS provides better monitoring on all services and delivers faster restoration mechanisms for all services and datastores.
Before we get to ReBid’s unique approach, let’s uncover the disaster recovery alphabet soup.
What is RPO and RTO?
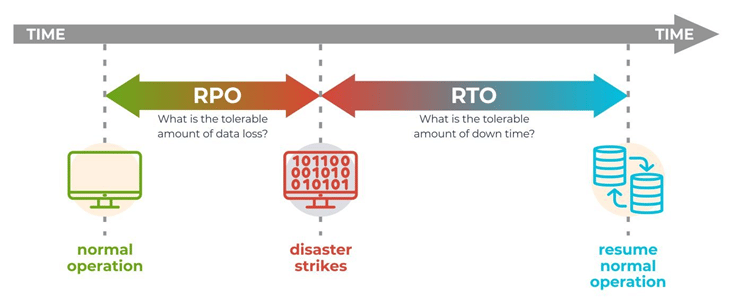
Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are the two significant terms one must understand in order to ensure disaster recovery and data protection. Having the right metrics for RPO and RTO help businesses decide on the most suitable cloud backup and disaster recovery strategy.
I think of the “RP” in “RPO” as “Rewrite Parameters” and the “RT” in “RTO” as “Real-Time,” to explain the differences.
What does RPO mean in cloud data protection?
Recovery Point Objective (RPO) indicates the amount of time that could pass during a disruption before the amount of data lost during that time exceeds the Business Continuity Plan’s tolerance limit.
For instance, if the business’s RPO is 20 hours and the most recent good copy of data is from an outage that occurred 18 hours ago, we are still inside the RPO’s outer limit. Alternatively, RPO answers a crucial question: Till which point in time could the business process’ recovery proceed tolerably given the volume of data lost during that interval?
What does RTO mean in disaster recovery solutions?
The Recovery Time Objective (RTO) is the amount of time and service level that a business process must be restored to following a disaster in order to prevent unacceptably negative impact by a break in business continuity. In other words, RTO answers: How long did it take to recover after the business process disruption was notified?
RPO indicates the variable amounts of data loss or amount of data that will need to be re-entered after a network outage. RTO stands for the amount of “real time” that can elapse before the disturbance starts to substantially and intolerably obstruct routine business operations.
How do you calculate RPO?
The RPO for your company depends on a variety of criteria, and it varies depending on the application. Some variables that may impact RPO include:
- Maximum data loss that a particular company can tolerate
- Factors related to the industry: Companies handling sensitive data, such financial transactions or medical records, must update more often
- The pace of recovery can be impacted by data storage choices, such as physical files versus cloud storage.
- The price of lost data and operations
- Compliance plans include measures for recovering from disasters, losing data, and having access to data that may damage organizations
- The price of putting catastrophe recovery systems in place
Cloud disaster recovery strategies
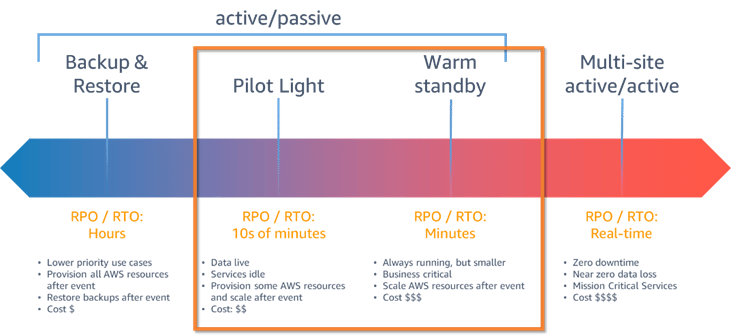
- Backup And Restore
Backup and Restore come in handy if your original data and applications are lost or damaged as a result of a power outage, cyberattack, human error, disaster, or any other unforeseen event. Backup refers to technologies and practices for periodically making copies (or backup) of the data and applications to a different secondary device or storage. Restore indicates using these backup copies to recover lost data and applications, and business operations that rely on these data sets and applications.
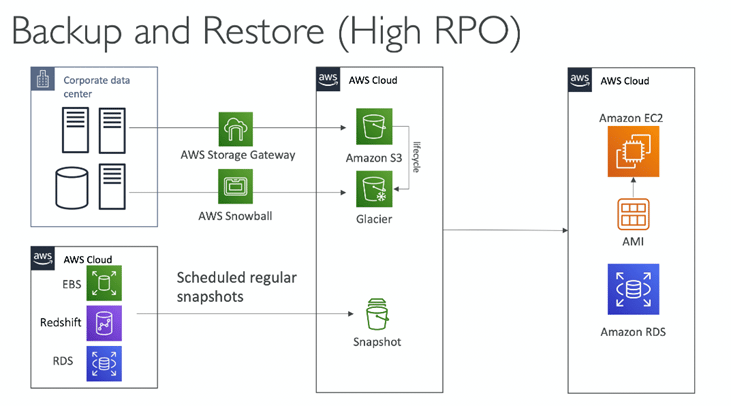
AWS Services for Backup & Restore
(a) AWS Backup
It is simple to consolidate and automate data protection across all AWS services, both in the cloud and on-premises. AWS offers a tool called AWS Backup, a fully managed service, to perform this action. AWS users can manage backup procedures and track the activity of AWS resources with this service. It eliminates the need to write unique scripts and manual procedures by enabling users to automate and combine backup actions that were previously carried out service-by-service.Your data protection schedules and policies can be automated with a few clicks in the AWS Backup dashboard.
| Supported resource | Supported resource type |
| Amazon Elastic Compute Cloud (Amazon EC2) | Amazon EC2 instances (excluding store-backed AMIs) |
| Windows Volume Shadow Copy Service (VSS) | Windows VSS-supported applications (including Windows Server, Microsoft SQL Server, and Microsoft Exchange Server) on Amazon EC2 |
| Amazon Simple Storage Service (Amazon S3) | Amazon S3 data |
| Amazon Elastic Block Store (Amazon EBS) | Amazon EBS volumes |
| Amazon DynamoDB | Amazon DynamoDB tables |
| Amazon Relational Database Service (Amazon RDS) | Amazon RDS database instances (including all database engines); Multi-Availability Zone clusters |
| Amazon Aurora | Aurora clusters |
| Amazon Elastic File System (Amazon EFS) | Amazon EFS file systems |
| FSx for Lustre | FSx for Lustre file systems |
| FSx for Windows File Server | FSx for Windows File Server file systems |
| Amazon FSx for NetApp ONTAP | FSx for ONTAP file systems |
| Amazon FSx for OpenZFS | FSx for OpenZFS file systems |
| AWS Storage Gateway (Volume Gateway) | AWS Storage Gateway volumes |
| Amazon DocumentDB | Amazon DocumentDB clusters |
| Amazon Neptune | Amazon Neptune clusters |
| VMware Cloud™ on AWS | VMware Cloud™ virtual machines on AWS |
| VMware Cloud™ on AWS Outposts | VMware Cloud™ virtual machines on AWS Outposts |
Users can also set cloudwatch events to copy the backup from one region to another region in case of regional outages.
(b) Amazon Data Lifecycle Manager
Amazon Data Lifecycle Manager allows users to create, store, and delete EBS snapshots and EBS-backed AMIs. Snapshot and AMI management automation includes several benefits like:
- Creating regular backup routines and enforcing them to protect mission-critical data
- Establishing standardized AMIs that can be updated regularly
- Retaining backups as required by auditors or compliance policies
- Reducing storage costs by deleting outdated backups
- Creating disaster recovery backup policies that store copies of data in isolated accounts
Amazon Data Lifecycle Manager offers a complete backup solution for Amazon EC2 instances and specific EBS volumes at no extra cost when combined with the monitoring capabilities of Amazon CloudWatch Events and AWS CloudTrail.
Other services included in AWS for Backup And Restore include:
Amazon DynamoDB Backup
Amazon EFS Backup (when using AWS Backup)
Amazon DocumentDB
2. Pilot Light
The app is constantly running a scaled-down version in the cloud. Pilot light is useful to protect the critical core, and is very comparable to backup and restore since the vital systems are already operational. However, pilot light works much faster than backup and restore. The pilot light strategy entails provisioning a duplicate of your core workload infrastructure and replicating your data from one region to another. Databases and object storage, required for data replication and backup, are constantly operational. Other components, such as application servers, are pre-configured and loaded with application code. However, they are only used during testing or when disaster recovery failover is required. You can easily provision resources when you need them and deprovision them when you no longer require them in the cloud. The resource should first be “turned off” by not being deployed. Then, the configuration and capabilities should be created so that the resource can be deployed (or “switched on”) as needed. Pilot light strategy keeps your core infrastructure always accessible, unlike the backup and restore method. It also gives you the choice to swiftly provide a large-scale production environment by turning on and scaling out your application servers.
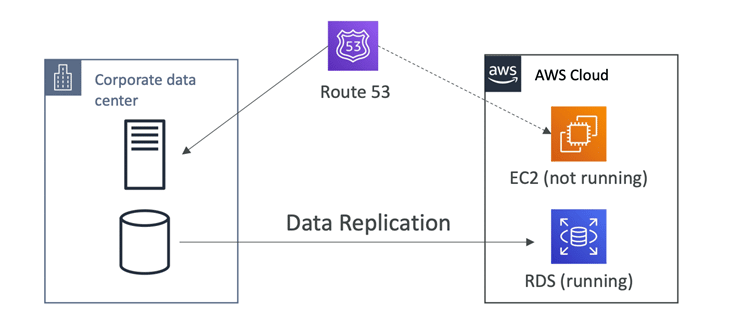
AWS Services for Pilot Light strategy
The ideal strategy for minimal RPO for pilot light is continuous data replication to live databases and data stores in the DR zone (when used in addition to point-in-time backups). When employing the following services and resources, AWS offers continuous, cross-region, asynchronous data replication. The AWS services for pilot light include:
- Amazon S3 Cross Region Replication
- Amazon RDS Read Replica
- Amazon Aurora Global Database
- Amazon DynamoDB Global Tables
- Amazon DocumentDB global clusters
- Global Datastore for Amazon Elasticache for Redis
Versions of your data are nearly immediately available in your DR Region due to continuous replication. Using service capabilities like S3 Replication Time Control for S3 items, you can track the actual replication times.
How ReBid ensures cloud disaster recovery
Over at ReBid, we have set up automated backup for mission-critical resources like databases and servers. We have containerised applications hosted on ECR and we also use EFS for unlimited scalability in some cases.
ReBid uses replica failovers on multiAZ in case of db failures. Our front-ends are on s3 and hosted via Cloudfront EdgeLocations. We are in the process of migrating to the Multi-site or Hot-site approach. Stay tuned for more on this.
In addition, we adhere to several security compliances, including Soc2 and GDPR.
What’s your approach for cloud data disaster recovery?? Leave a comment and do share your experiences from the trenches of business continuity and disaster recovery.


